一、写在前面
为什么要进行数据切分:
随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题。对于一个大型的互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载。对于系统的稳定性和扩展性造成了极大的问题。通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式。
数据库优化的策略
- 水平切分数据库,可以降低单台机器的负载,同时最大限度的降低了了宕机造成的损失。
- 通过负载均衡策略,有效的降低了单台机器的访问负载,降低了宕机的可能性;
- 通过集群方案,解决了数据库宕机带来的单点数据库不能访问的问题;
- 通过读写分离策略更是最大限度了提高了应用中读取(Read)数据的速度和并发量。
二、MySQL分库分表方案
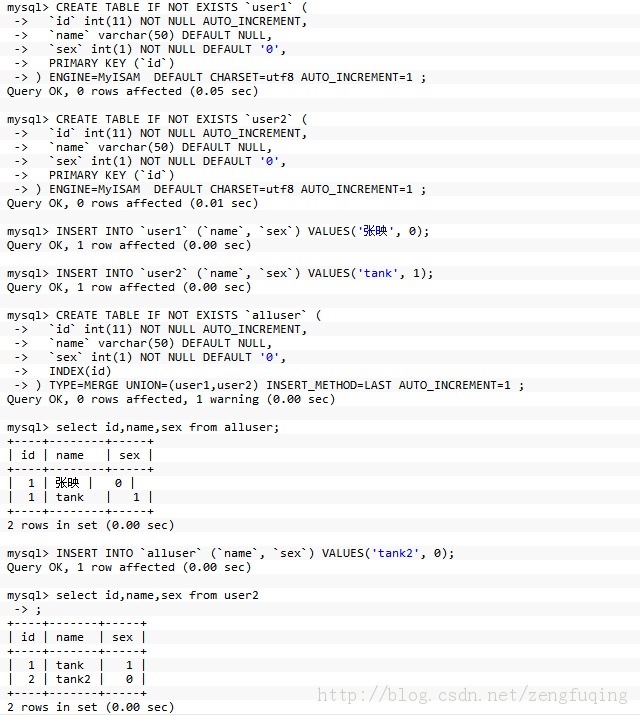
1、利用merge存储引擎来实现分表(水平分表)
-
merge引擎实现MySQL分表,这种方法比较适用于没有事先考虑分表,而随着数据量增大,查询速度减慢的情况
-
merge的要求:
- 合并的表使用的必须是MyISAM引擎
- 表的结构必须一致,包括索引、字段类型、引擎和字符集
-
示例
2、简单的MySQL主从复制
-
MySQL的主从复制解决了数据库的读写分离,并很好的提升了读的性能
- 主数据库负责写,从数据库负责读,主库写入数据后会同步到从库
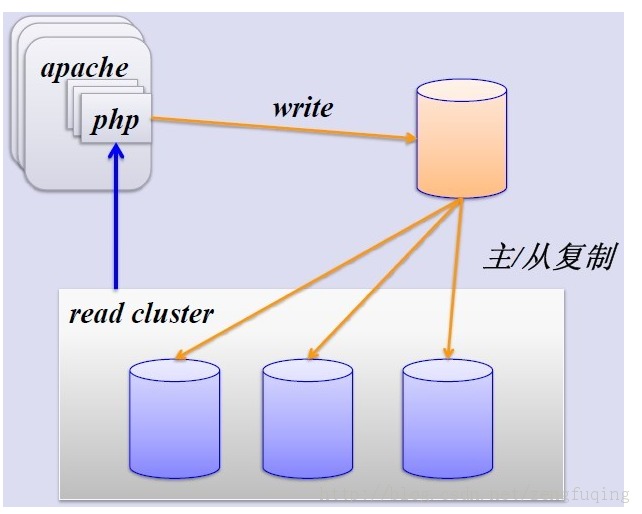
- 主数据库负责写,从数据库负责读,主库写入数据后会同步到从库
-
仍存在的问题:
- 写入无法扩展和缓存
- 主从的数据复制存在延迟
- 锁表率上升
- 表变大,缓存率下降
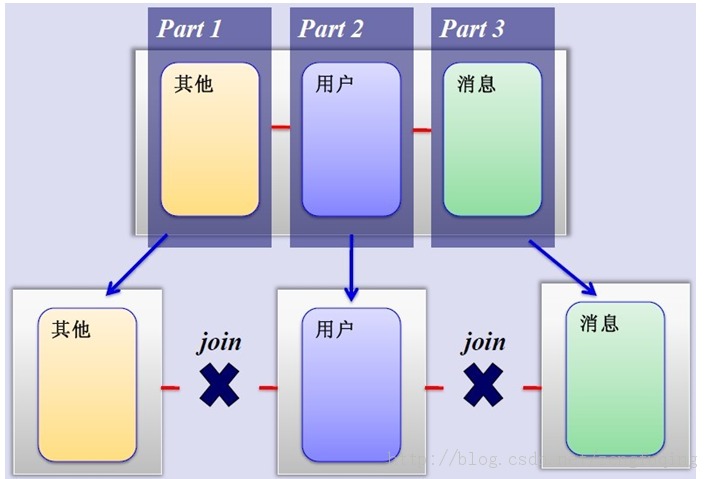
3、MySQL垂直分区
- 如果业务足够独立,可以将不同业务的数据垂直切割到不同的数据库,起到负载分流的作用,大大提升了数据库的吞吐能力,垂直切割如下图
4、MySQL水平分片(sharding)
- 切片方式:
- 物理切片:通过路由规则访问特定的数据库
- 数据切片: 对数据进行一系列的切分规则,将数据分布到数据库的不同表中
- 基于水平分片的三种分库方式和规则
-
按号段分:如user_id的1~1000对应DB1,1001~200对应DB2…
- 优点:可迁移部分数据
- 缺点:数据分布不均匀
-
hash取摸分:对user_id的哈希进行取模(如hash(user_id) % n),n为要分的数据库数量
- 优点:数据分布均匀
- 缺点:数据迁移的时候比较麻烦,不能按机器性能分摊数据
-
在认证库中保存数据库配置:建立一个DB,这个DB单独保存user_id到数据库的映射关系,每次访问的时候都先查询下认证库,从而得到user_id存储的DB信息。
- 优点:灵活性强,一对一的关系
- 缺点:每次查询都需要先进行一次查询,性能大打折扣
-
-
分布式数据方案提供功能如下:
- 提供分库规则和路由规则(RouteRule简称RR),可将上面提供的三种分片规则直接内嵌入系统。
- 引入集群(Group)概念,保证数据的高可用性。
- 引入负载均衡策略(LocalBalancePollcy,简称LB)
- 引入集群节点可用性探测机制,对单点机器的可用性进行定时的定制,以保障LB策略的正确实施,确保系统的高度稳定性。
- 引入读写分离,提高数据的查询速度。
-
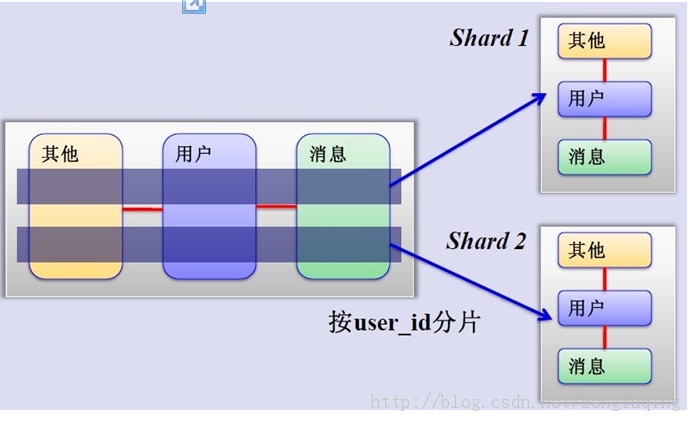
哈希取模分片简介:
-
将用户按照一定的规则**(按ID哈希)分组,并把该用户的数据存储到一个数据库分片**中,即一个sharding,随着用户的增加,只需要简单的配置一台服务器即可。原理如下图:
-
获取分片存储的信息如下(先创建一张用户和shard对应的数据表,用于查找用户的shard id,再从对应shard id查找相关数据):
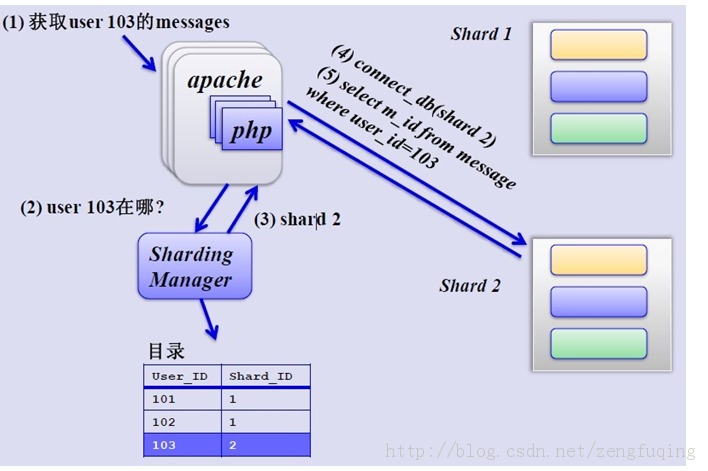
-
5、对冷热数据的处理
-
举例:在一个博客系统中,文章标题,作者,分类,创建时间等,是变化频率慢,查询次数多,而且最好有很好的实时性的数据,我们把它叫做冷数据。而博客的浏览量,回复数等,类似的统计信息,或者别的变化频率比较高的数据,我们把它叫做活跃数据。
-
处理方法:
- 存储引擎的使用不同,冷数据使用MyIsam可以有更好的查询数据。活跃数据,可以使用Innodb ,可以有更好的更新速度。
- 对冷数据进行更多的从库配置,因为更多的操作是查询,这样来加快查询速度。对热数据,可以相对有更多的主库的横向分表处理。
- 对于一些特殊的活跃数据,也可以考虑使用memcache,redis之类的缓存,等累计到一定量再去更新数据库

