一、分布式锁的原理
场景:多实例的代码块同步(单实例通信基于本机环境,多实例通信借助第三方)
锁通常用于做代码块的同步,保证同段代码在多线程情况下同一时间只能被一个线程执行。Java中用于锁操作的有Synchronize和ReentranLock,但是两者都是基于单机应用的情况下使用,对于分布式系统,同个服务会有多个实例被启动(例如多实例下保证单个定时任务执行),那么对于这种场景下的代码块同步就不能按常规处理,只能借助第三方让各个实例进行通信,进而达到锁的控制效果,目前分布式锁常见的实现方式有:基于数据库行锁、基于Redis锁、基于Zookeeper锁。
流程:多实例做锁的抢占,加锁成功的获取到锁并执行相关代码块,此时其他实例获取锁失败,完成操作后解锁。
二、分布式锁的实现方案及优缺点
临界知识:
- 分布式锁本质上就是多实例的锁抢占问题。
1. 基于数据库的分布式锁
实现原理
-
分布式锁在MySQL上的体现本质上就是多实例间基于数据库表的锁抢占过程。其中会用到MySQL的一些锁的特性。
-
MySQL有哪些锁?
- 按照锁的粒度分有:行锁和表锁(都是悲观锁)。InnoDB支持两者,MyIsam只支持表锁。行锁是基于索引进行的,如果查询没走索引,则说明需要进行全表扫描,加的也是表锁。
- 按照锁的功能分有:读锁(共享锁)和写锁(排他锁)。
- 按照锁的实现方式分有:悲观锁和乐观锁。
-
MySQL在执行Select语句之前会加读锁,Delete、Update、Insert语句前会加写锁(悲观锁)。
实现方式
隐式加锁
- 基于数据库表:直接创建一张表
- 加锁:向表中插入一条数据(主键或唯一键),插入成功则说明获取到锁。
- 解锁:删除该行数据
显式加锁
-
悲观锁:在SQL语句中显式做锁竞争
- 加锁:在语句后面 + for update修改锁状态,修改成功则锁抢占成功
- 解锁:将锁状态修改回来
// 在同个事务中for update的锁会一直持有,该例子只是单实例加锁演示,但是for update确实可以用于锁的抢占。 //0.开始事务 begin;/begin work;/start transaction; (三者选一就可以) //1.查询出商品信息 select status from t_goods where id=1 for update; //2.根据商品信息生成订单 insert into t_orders (id,goods_id) values (null,1); //3.修改商品status为2 update t_goods set status=2; //4.提交事务 commit;/commit work; -
乐观锁:在SQL语句中显式做锁竞争
- 加锁:update并修改锁状态成功则说明锁抢占成功。(用于做锁抢占的语句本质上没有加锁,不过每次都会校验当前版本,版本号不同则回滚。)
- 解锁:将锁状态改回则解锁成功
1.查询出商品信息 select (status,status,version) from t_goods where id=#{id} 2.根据商品信息生成订单 3.修改商品status为2 update t_goods set status=2,version=version+1 where id=#{id} and version=#{version};
优缺点
-
对数据库依赖,存在
- 单点故障
- 不走索引时行锁会变表锁,导致并发性能降低
- 锁不可以重入
2. 基于Redis的分布式锁
实现原理
-
Redis是单线程的,天生不需要做锁抢占
-
通过其
set nx命令可以实现加锁:当redis中不存在该key时返回成功,否则返回失败 -
通过
px命令,可以实现超时解锁:指定时间后做锁的释放
实现方式
基于Redisson的实现
流程:客户端A向redis集群申请锁,redisson根据hash算法选择一个节点,并执行lua脚本加锁,lua脚本主要进行了以下步骤:【判断锁是否存在,不存在则setnx并且通过px命令添加超时时间,用于保证多个指令的原子性,防止程序运行到一半宕机导致的脏数据生成】。加锁成功后,redisson有watch dog机制,每隔一段时间去检测该锁的超时时间延长,防止业务还没执行完锁就被超时释放的情况。如果此时客户端B申请锁,发现锁被占用,则循环尝试不断加锁。待客户端A完成业务并通过lua脚本释放锁后,B获取锁。
RLock lock = redisson.getLock("myLock");
lock.lock();
lock.unLock();
原理:
- 加锁:lua脚本加锁(key name,expire time,客户端Id)
- 锁的互斥机制:单线程判断key是否存在
- 解锁:lua脚本解锁(key name)
常见问题:
lua脚本是的作用是什么?
由于Redis的setnx命令和px命令不是原子性的,如果setnx成功而px失败,则会导致锁一直存在。lua脚本就是为了保证多条命令的原子性。
lua脚本的本质是什么?
lua脚本本质上类似于开启了事物,跟MySQL开启事物类似,从客户端的角度上看,就是只有完全执行成功的脚本命令才可见,执行一半是不可见的(隔离级别:已提交读。
watch dog的作用是什么?
由于用户在设置锁的超时时间的时候,无法把握时间长短,可能会出现以下情况:业务还没执行完,锁就被释放了。为了解决这个问题,watch dog自动延期机制被开发出来,主要遵循以下原则:
1. 每隔一段时间向redis服务器查看锁是否存在,存在则延长超时时间。
2. 当用户的工作线程出错的时候,watch dog协程则会终止延时,保证锁会被超时释放。
优点:
-
分布式主从节点,避免单点故障
-
锁的可重入性(每次进入会检查锁的客户端Id是否相同,相同则锁的数量+1,解锁的时候-1,直到0)
-
基于内存的锁操作,性能更高。
-
防死锁机制:超时解锁(watch dog做配对实现超时延时)
缺点:
-
master节点如果来不及同步到slave就挂了,重新选举后会导致另外的客户端获取到该锁,及同个锁被多个用户获取,导致脏数据的产生。
基于RedLock算法的实现
为了解决上述的同步问题,redis作者提出了基于RedLock算法的解决方案,大致内容如下(本质上是让多个节点上存储锁,redisson已经整合):
- 加锁的时候,RedLock算法会尝试在大多数节点上分别创建锁,假如节点总数为n,那么大多数节点指的是n/2+1。
- 客户端计算成功建立完锁的时间,如果建锁时间小于超时时间,就可以判定锁创建成功。如果锁创建失败,则依次(遍历master节点)删除锁。
3. 基于Zookeeper的分布式锁
流程:(Curator框架整合了zk)
客户端A向Zookeeper申请锁,此时zookeeper会创建一个用于发号的锁节点(顺序节点),zk会在该节点下维护的顺序序号,每个来申请锁的客户端都会依次获得一个序号,获得序号后,客户端会来查看自己的序号是否是最小的序号,如果是则加锁成功。
如果此时客户端B申请锁,同样或许序号后发现自己的序号不是最小序号,则会创建一个监听器,监听上一个序号是否被删除等变化,如果该序号被删除(客户端A完成业务后删除序号释放锁),则会通知客户端B。
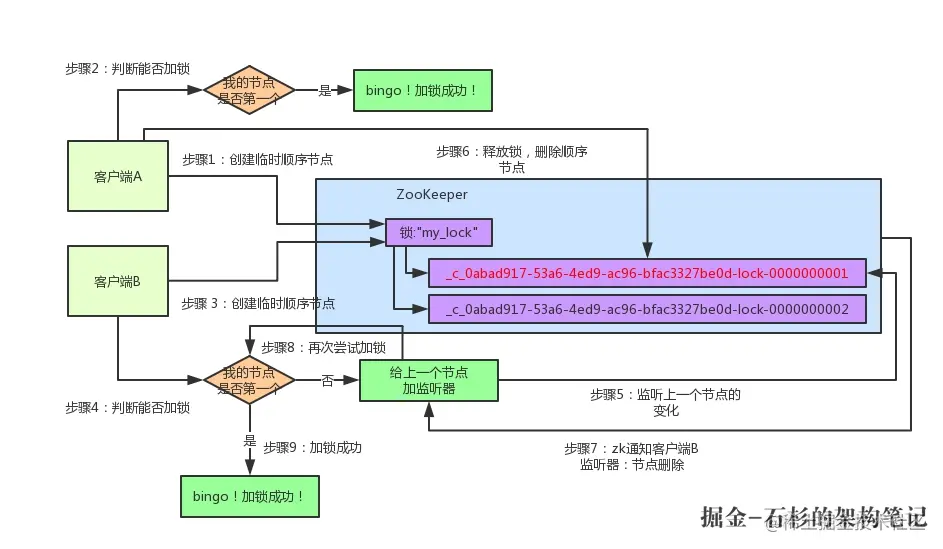
原理:
-
加锁:zk发号器发放顺序序号并且发放的序号为最小序号,则加锁成功
-
锁的互斥:zk线程安全的顺序发号器(不同客户端请求获取的锁序号不同,底层可能是加乐观锁或悲观锁)
-
解锁:客户端完成业务后,删除序号(监听器会监听并通知下一个序号)。
常见问题:
如果客户端宕机了,如何防止死锁?
zk提供了防死锁机制,zk会监听客户端是否存活,如果监测到不存活则删除对应的序号。
优点:
- 主动通知客户端锁释放
- 锁的可重入
- 防死锁机制:监听客户端是否存活,如果不存活则删除对应的锁序号。

